Most incident response documentation gets written after the first major incident, not before.
The team has just spent hours fighting a production outage. Two engineers worked from memory. One engineer followed an old wiki page that referenced a dashboard nobody uses anymore.
The retro happens. Someone writes “we need runbooks” as an action item.
Three months later, the runbooks are still not done.
This guide takes the opposite approach. It explains the four artifacts that make up a useful incident response documentation library, then walks through a practical way to build runbooks before the next outage.
The focus here is operational reliability, not just cybersecurity. The same structure works for database failovers, payment outages, ransomware events, misconfigured deployments, and cloud incidents.
Key takeaways
- Incident response documentation tells responders what to do when something breaks.
- A working library includes four artifacts: incident response policy, service runbooks, severity playbooks, and postmortem records.
- Runbooks are per-service and per-failure-mode. Playbooks are cross-system and per-severity. Teams often confuse the two.
- The biggest mistake is writing runbooks from memory after an incident. Capture-first authoring creates better runbooks because it records the real procedure.
- A useful runbook includes scope, trigger, severity, access, diagnostics, resolution, escalation, communication, and a last-verified date.
What is incident response documentation?
Incident response documentation is the set of written artifacts that tells responders what to do when a system is failing, degraded, or under attack.
It covers:
- Order of operations
- Roles and authority
- Escalation rules
- Communication steps
- Recovery procedures
- Post-incident learning
- The audience changes by artifact.
- On-call engineers need runbooks. Incident commanders need playbooks. Leadership, auditors, and legal teams need policy. Future responders need postmortems.
- Most teams get into trouble when they treat all of those as one document.
- They are not one document. They are four different artifacts with different jobs.
Why most incident response documentation gets written after the first sev1
Three forces push incident response documentation into the "after the incident" timing window.
First, the work is hard to justify in advance. Writing runbooks for systems that have not failed yet feels like overhead, especially when the engineering backlog is full of revenue-driving features. The cost of the runbook is concrete (engineering hours). The benefit is hypothetical (faster recovery from an outage that may not happen this quarter).
Second, the work is hard to assign. SREs say it belongs to the service owners. Service owners say it belongs to SRE. Both are partially right, which means it usually falls between the two and gets done by neither.
Third, the work is hard to keep current. A runbook authored in March is half-stale by September because the underlying console, alert names, and dependencies have all moved. The team writes the runbook, the runbook ages, the next incident hits, the runbook is wrong, and the team concludes "runbooks are useless." That conclusion is wrong but rational given the failure mode.
The fix is not "write more runbooks." It is to switch the authoring model. The runbook needs to be cheap enough to write before the incident and cheap enough to refresh after every relevant change. Capture-first authoring (record the procedure once, regenerate when the UI changes) makes both halves of that economics work.
For the wider category context, see our work on process documentation best practices and how teams document workflows without writing a single word.
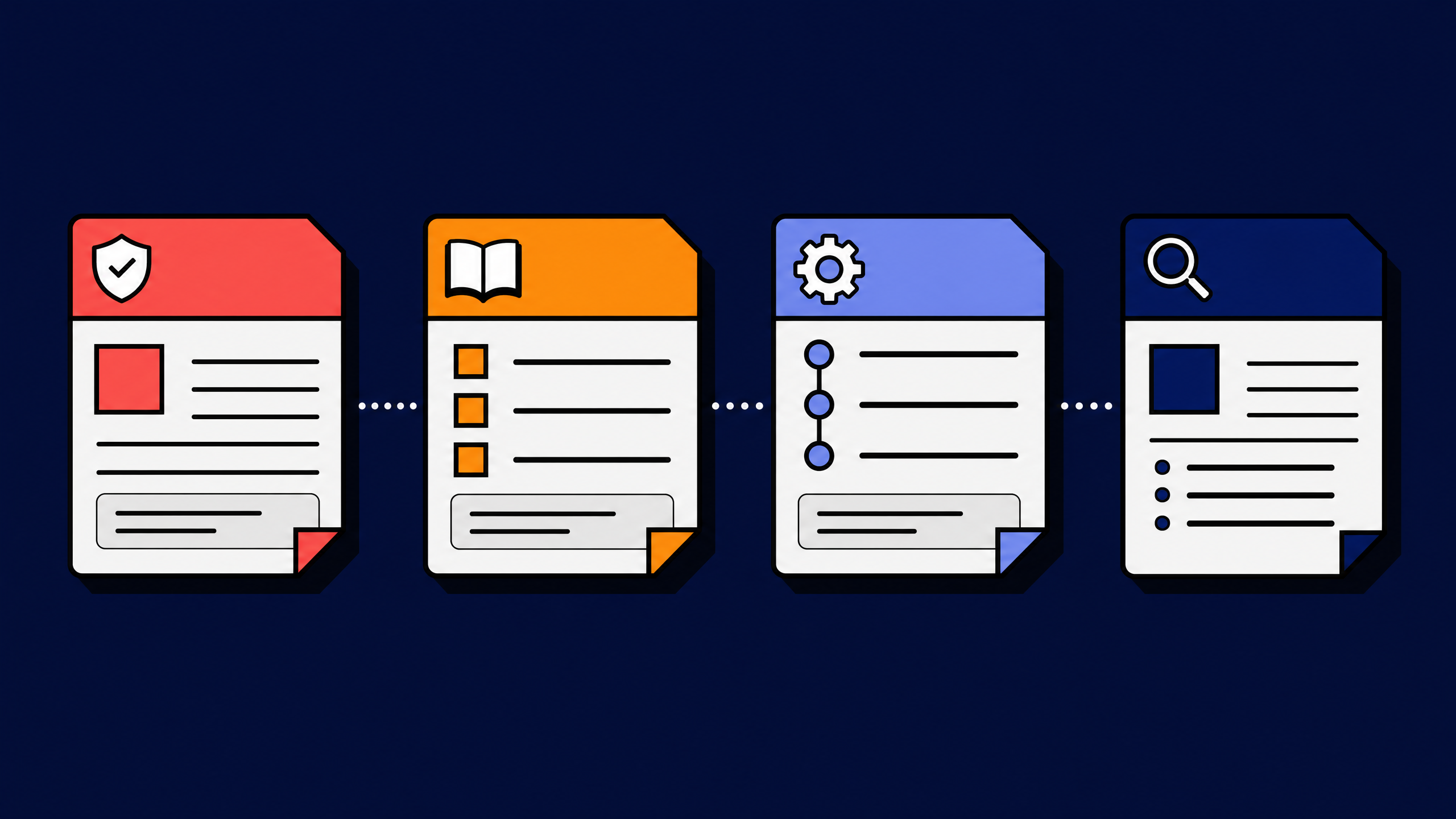
The 4 artifacts every incident response documentation library needs
Every working incident response documentation library carries 4 artifact types. The artifacts answer different questions, target different audiences, and have different update cadences. Most failed libraries ship one or two and call it done.
1. The incident response policy (the IRP)
The IRP is the high-level governance document. It defines what counts as an incident, how severities are classified, and who declares and commands them. It also names the organization's commitments on communication, escalation, and regulatory disclosure. The audience is leadership, auditors, customers asking about your security posture, and the legal team during a breach.
The IRP is the artifact most NIST-style guides cover at length. It is also the artifact that responders almost never read at 2 a.m. It is required for SOC 2, ISO 27001, and most enterprise customer security reviews. Update cadence: annual review minimum.
2. Service runbooks (the per-system SOPs)
A service runbook is a per-service, per-failure-mode procedure. Common examples:
- What to do when the payments database is showing replication lag.
- What to do when the CDN origin is returning 503s.
- What to do when the API rate limit is exhausted on the upstream provider.
Each runbook covers one service and one or a few related failure modes. The audience is the on-call engineer who got paged. The runbook should be readable in under 60 seconds and actionable in under 5 minutes. Update cadence: every time the underlying console or alert name changes, which in practice means quarterly at minimum.
3. Severity-tier playbooks (the cross-system response flows)
A playbook covers cross-system response. Common examples:
- How we run a sev1 incident.
- How we coordinate a security incident involving customer data.
- How we handle a regional cloud outage.
The playbook tells the incident commander how to declare, communicate, escalate, and stand down across multiple teams. The audience is the incident commander. The playbook is severity-tiered: sev1 has a different playbook from sev3 because the cross-functional coordination requirements differ. Update cadence: after each sev1 retrospective, plus an annual full review.
4. Postmortem records (the institutional memory)
A postmortem is the structured record of what happened during a specific incident: timeline, contributing factors, customer impact, action items, ownership. The audience is the next responder who hits a similar failure mode, plus the engineering team running the longer-term fix work.
Postmortems are the only artifact that can never be written before the incident. They are also the artifact most likely to be skipped because the team is exhausted afterwards. Update cadence: one per incident, written within 72 hours.
Artifact takeaways
The incident response policy is for governance.
The runbook is for the on-call engineer.
The playbook is for the incident commander.
The postmortem is for future responders.
If your documentation stops at the policy layer, it will not help much during the incident itself.
How to build runbooks before you need them: the pre-incident playbook
This is the operational core of the article. The 4-artifact taxonomy above tells you what to write. The 5 steps below tell you how to actually get the most-needed artifact (the service runbook) done before the next sev1.
Step 1: Inventory the services that can page someone at 2 a.m.
Start with the alert routing config. Every alert that pages a human is a runbook candidate. Pull the list from PagerDuty, Opsgenie, Splunk On-Call, or whatever pages your team. Cluster by service.
Most organizations are surprised by how short the list actually is once duplicates are merged. A 50-engineer SaaS team usually has between 15 and 25 runbook-worthy services, not 100.
Rank the services by 90-day page volume. The top 5 services account for most of the on-call load. Those 5 get runbooks first. The long tail can wait.
Step 2: Write the runbook by capture, not by recall
Recall is the wrong authoring model for runbooks. The procedure is in the engineer's hands, not the engineer's head. Writing it down by typing takes 5 to 10 times longer than executing it.
Capture-first authoring inverts this. The engineer runs the procedure once during a calm-time dry run and captures it on screen. The tool generates a numbered step-by-step guide with screenshots automatically.
Two side benefits. The captured runbook reflects the current UI, not the UI from when the engineer first learned the system. The captured runbook also surfaces the steps the engineer takes unconsciously. That is the institutional knowledge most likely to be lost when the on-call rotation changes.
Step 3: Include the boring runbook fields most teams skip
A runbook that only contains resolution steps fails at 2 a.m. The on-call engineer is missing context that the original author had implicitly. The runbook needs the boring fields too:
Which alert it responds to.
Which severity it implies.
Which credentials are required.
Which escalation path applies if the resolution does not work.
The 9-section template below covers the full list.
The single most-skipped field is "last verified date." Without it, the responder cannot tell whether the runbook is fresh or stale. With it, the responder makes a fast trust decision. A 6-week-old verified date earns trust. A 6-quarter-old date earns a verify-before-acting reflex.
Step 4: Test the runbook with a no-context dry run
A runbook is useful only if a person who did not write it can execute it. Test by handing the runbook to an engineer who has never worked the relevant service.
Ask them to run it end to end with no context other than the runbook itself. Time how long it takes. Note every place they had to ask a question.
The questions are the runbook bugs. Fix them in the runbook, not by training the next engineer. Re-test until a no-context engineer can run the runbook without external help. This is the most predictive test of runbook quality, and the test most teams skip.
Step 5: Tie the runbook to the alert that fires it
A runbook nobody can find at 2 a.m. is a runbook that does not exist. Wire the runbook URL into the alert payload directly. Common alerting tools that support runbook URL fields:
PagerDuty (runbook field on services).
Datadog monitors.
Splunk On-Call (now Splunk Incident Intelligence).
Opsgenie (runbook URL on alert policies).
Whatever your alerting tool, the link to the runbook should appear in the page itself, not in a wiki the engineer has to search.
The wiring also creates a feedback loop. When the runbook is missing, the alert payload makes the gap obvious. When the runbook is wrong, the responder knows exactly which document to update.
For the broader runbook-authoring shift, see our coverage of AI process documentation and the IT-team-specific framework in IT documentation software, feature 2.
A useful runbook template (the 9-section pattern)
Every runbook in the library should follow the same 9-section pattern. Uniformity matters. The on-call engineer should not have to re-learn the runbook structure for each service. The template below is the one we have seen survive vendor UI changes and team rotations.
The first 6 sections are the runbook content. Sections 7 to 9 are the operational metadata that make the runbook usable under pressure. Most failed runbook libraries skip sections 7 to 9 entirely. The result is runbooks that work in a tabletop exercise and fail in a real incident.
For a deeper SOP-pattern library applicable to runbook authoring, see our 12 SOP patterns that survive UI changes.
What is the difference between a runbook and a playbook?
This is the most-asked question in the incident response documentation cluster, and the source of most documentation-library confusion. Worth handling head-on.
A runbook is per-service and per-failure-mode. It tells one engineer how to resolve one specific issue on one specific system. The audience is the on-call engineer. The output is a system back to healthy.
A playbook is cross-system and per-severity. It tells the incident commander how to coordinate across multiple teams during an incident at a given severity tier. The audience is the incident commander. The output is a coordinated response with clear roles and clear communication.
Both artifacts are needed. A team that has runbooks but no playbook flounders at high severity. Nobody knows who is in charge of cross-team coordination. A team that has a playbook but no runbooks has process but no operational knowledge.
Common mistakes when documenting incident response
Five mistakes show up repeatedly across incident response documentation libraries that get rebuilt within 18 months.
Mistake 1: writing the IRP first and never getting to the runbooks
The IRP is the easiest artifact to write because it is mostly policy language. It is also the artifact that responders never read at 2 a.m. Teams that ship the IRP and stop have a documentation library optimized for auditors and useless to operators. Write the IRP, then write the runbooks for the top 5 page-volume services within the same quarter.
Mistake 2: shipping one document that tries to be both runbook and playbook
A combined document fails both jobs. It is too long for a runbook because the on-call engineer cannot scan it in 60 seconds. It is too shallow for a playbook because the incident commander cannot use it to coordinate.
Split the documents. Use the 9-section runbook template above for runbooks. Use a separate severity-tier playbook structure for cross-functional flows.
Mistake 3: authoring runbooks by recall instead of capture
Recall produces runbooks that match the engineer's memory of the UI, not the current UI. By the time the runbook is written, half the screenshots are wrong. Capture-first authoring (record once, regenerate when the UI changes) collapses both the initial authoring time and the maintenance time.
Mistake 4: skipping the no-context dry run
A runbook that the original author can execute is not the same as a runbook anyone can execute. The original author has implicit context the runbook does not capture. Test by handing the runbook to an engineer with no service knowledge and watching where they get stuck. Fix the gaps in the runbook, not in the next engineer's training.
Mistake 5: not tying runbooks to the alert that fires them
A runbook nobody can find at 2 a.m. is a runbook that does not exist. Wire the runbook URL into the alert payload itself. The link should appear in the page the engineer receives, not in a wiki they have to search.
Mistake-avoidance takeaways
Ship runbooks within the same quarter as the IRP, not after.
Split runbooks and playbooks. They serve different audiences and different jobs.
Capture, do not recall. Recall produces stale screenshots.
Test with a no-context dry run. The questions are the runbook bugs.
Wire the runbook URL into the alert. A runbook that requires search does not exist.
How long should building incident response documentation actually take?
For a mid-sized engineering team starting from scratch, expect several weeks of focused, part-time work.
A practical six-week sprint looks like this:
- Week 1: Inventory alerts, group by service, rank by page volume and risk.
- Week 2: Draft or update the incident response policy.
- Weeks 3–4: Capture runbooks for the top services using the 9-section template.
- Week 5: Write severity-tier playbooks for sev1 and sev2 coordination.
- Week 6: Run a tabletop exercise, fix gaps, and wire runbook links into alerts.
- After that, maintenance should be built into normal operations.
- Review runbooks quarterly, after major service changes, and after any incident where the runbook was used or found lacking.
FAQ
What is incident response documentation?
Incident response documentation is the set of written artifacts that tells responders what to do when a system is failing or under attack. It usually includes an incident response policy, service runbooks, severity playbooks, and postmortem records.
What should an incident response runbook include?
A working runbook should include scope, trigger, severity, required access, diagnostics, resolution steps, escalation path, communication template, and a last-verified date with owner.
How do you document an incident response plan?
Start with the policy layer, then create runbooks for the highest-risk services, add severity-tier playbooks, and write postmortems after major incidents. The policy explains the overall approach; the runbooks and playbooks make it operational.
What is the difference between a runbook and a playbook?
A runbook is per-service and per-failure-mode. It helps one engineer fix one specific issue. A playbook is cross-system and per-severity. It helps the incident commander coordinate the response.
How often should incident response runbooks be updated?
Update runbooks whenever alerts, dependencies, dashboards, consoles, or recovery steps change. At minimum, review them quarterly and after incidents.
Where should incident response documentation live?
Where the responder can reach it quickly. The runbook can live in a wiki, structured documentation tool, or capture-first SOP tool, but the URL should be linked directly in the alert payload.
What is an incident response framework?
An incident response framework is a methodology for handling incidents from preparation through recovery and post-incident review. NIST, SANS, AWS, Google SRE, and Atlassian all publish well-known frameworks. The framework shapes the policy layer; runbooks and playbooks make it actionable.